本文共 18320 字,大约阅读时间需要 61 分钟。
目录
为了大厂的面试offer,今天给大伙介绍Tomcat组件结构+Nginx性能调优
对于tomcat的核心技术我觉得可以分为这些:
如图

tomcat的基本配置:
而Tomcat的基本配置,每个配置项也基本上对应了Tomcat的组件结构,如果要用一张图来形象展现一下Tomcat组成的话,整个Tomcat的组成可以如下图所示:
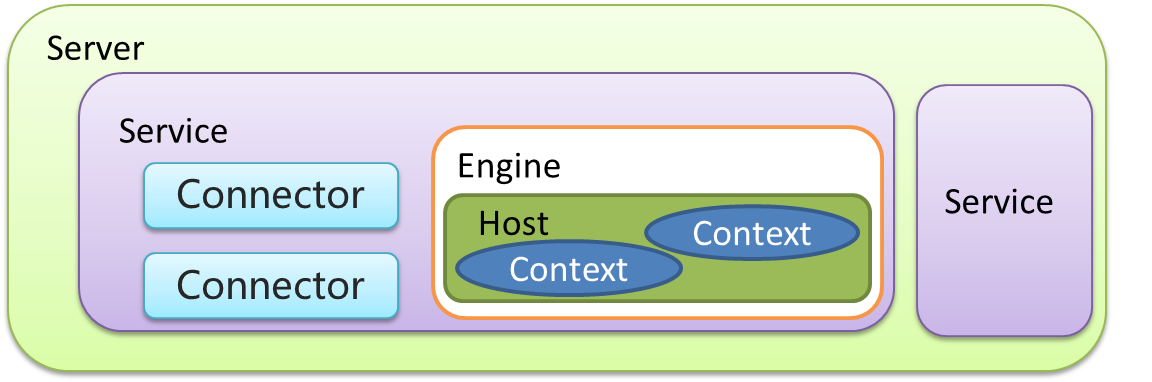
tomcat收听请求,如何响应?
Tomcat在接收到用户请求时,将会通过以上组件的协作来给最终用户产生响应。首先是最外层的Server和Service来提供整个运行环境的基础设施,而Connector通过指定的协议和接口来监听用户的请求,在对请求进行必要的处理和解析后将请求的内容传递给对应的容器,经过容器一层层的处理后,生成最终的响应信息,返回给客户端。
Tomcat的容器通过实现一系列的接口,来统一处理一些生命周期相关的操作,而Engine、Host、Context等容器通过实现Container接口来完成处理请求时统一的模式,具体表现为该类容器内部均有一个Pipeline结构,实际的业务处理都是通过在Pipeline上添加Valve来实现,这样就充分保证整个架构的高度可扩展性。Tomcat核心组件的类图如下图所示:
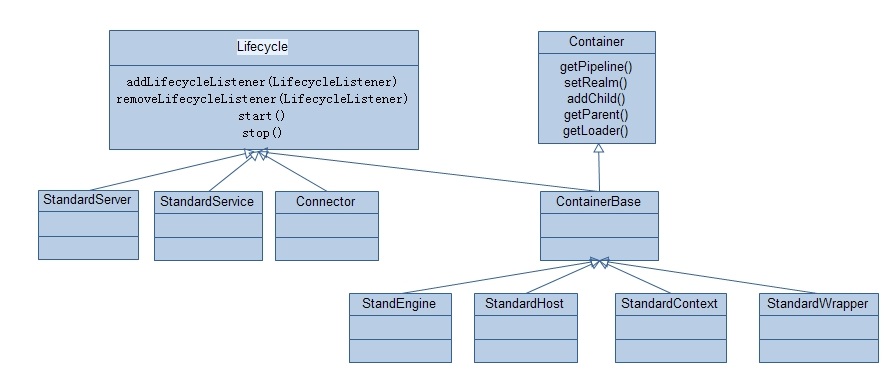
在介绍请求的处理过程时,将会详细介绍各个组件的作用和处理流程。本文将会主要分析Tomcat的启动流程,介绍涉及到什么组件以及初始化的过程,简单期间将会重点分析HTTP协议所对应Connector启动过程。
Tomcat在启动时的重点功能如下:
-
初始化类加载器:主要初始化CommonLoader、CatalinaLoader以及SharedLoader;
-
解析配置文件:使用Digester组件解析Tomcat的server.xml,初始化各个组件(包含各个web应用,解析对应的web.xml进行初始化);
-
初始化连接器:初始化声明的Connector,以指定的协议打开端口,等待请求。
不管是通过命令行启动还是通过Eclipse的WST server UI,Tomcat的启动流程是在org.apache.catalina.startup. Bootstrap类的main方法中开始的,在启动时,这个类的核心代码如下所示:
public static void main(String args[]) { if (daemon == null) { daemon = new Bootstrap();//实例化该类的一个实例 try { daemon.init();//进行初始化 } catch (Throwable t) { ……; } } try { ……//此处略去代码若干行 if (command.equals("start")) { daemon.setAwait(true); daemon.load(args);//执行load,生成组件实例并初始化 daemon.start();//启动各个组件 } ……//此处略去代码若干行 } 从以上的代码中,可以看到在Tomcat启动的时候,执行了三个关键方法即init、load、和start。后面的两个方法都是通过反射调用org.apache.catalina.startup.Catalina的同名方法完成的,所以后面在介绍时将会直接转到Catalina的同名方法。首先分析一下Bootstrap的init方法,在该方法中将会初始化一些全局的系统属性、初始化类加载器、通过反射得到Catalina实例,在这里我们重点看一下初始化类加载器的方法:
private void initClassLoaders() { try { commonLoader = createClassLoader("common", null); if( commonLoader == null ) { // no config file, default to this loader - we might be in a 'single' env. commonLoader=this.getClass().getClassLoader(); } catalinaLoader = createClassLoader("server", commonLoader); sharedLoader = createClassLoader("shared", commonLoader); } catch (Throwable t) { log.error("Class loader creation threw exception", t); System.exit(1); } }
在以上的代码总,我们可以看到初始化了三个类加载器,这三个类加载器将会有篇博文进行简单的介绍。
进入Catalina的load方法:
然后我们进入Catalina的load方法:
public void load() {//…… //初始化Digester组件,定义了解析规则 Digester digester = createStartDigester(); //……中间略去代码若干,主要作用为将server.xml文件转换为输入流 try { inputSource.setByteStream(inputStream); digester.push(this);//通过Digester解析这个文件,在此过程中会初始化各个组件实例及其依赖关系 digester.parse(inputSource); inputStream.close(); } catch (Exception e) { } // 调用Server的initialize方法,初始化各个组件 if (getServer() instanceof Lifecycle) { try { getServer().initialize(); } catch (LifecycleException e) { if (Boolean.getBoolean("org.apache.catalina.startup.EXIT_ON_INIT_FAILURE")) throw new java.lang.Error(e); else log.error("Catalina.start", e); } } } 在以上的代码中,关键的任务有两项即使用Digester组件按照给定的规则解析server.xml、调用Server的initialize方法。关于Digester组件的使用,后续会有一篇专门的博文进行讲解,而Server的initialize方法中,会发布事件并调用各个Service的initialize方法,从而级联完成各个组件的初始化。每个组件的初始化都是比较有意思的,但是我们限于篇幅先关注Connector的初始化,这可能是最值得关注的。
Connector的initialize方法,核心代码如下:
public void initialize() throws LifecycleException{ //该适配器会完成请求的真正处理 adapter = new CoyoteAdapter(this); //对于不同的实现,会有不同的ProtocolHandler实现类,我们来看 //Http11Protocol,它用来处理HTTP请求 protocolHandler.setAdapter(adapter); try { protocolHandler.init(); } catch (Exception e) { …… } } 在Http11Protocol的init方法中,核心代码如下:
public void init() throws Exception { endpoint.setName(getName());//endpoint为JIoEndpoint的实现类 endpoint.setHandler(cHandler); try { endpoint.init();//核心代码就是调用 JIoEndpoint的初始化方法 } catch (Exception ex) { …… } } 我们看到最终的初始化方法最终都会调到JIoEndpoint的init方法,网络初始化和对请求的最初处理都是通过该类及其内部类完成的,所以后续的内容将会重点关注此类:
public void init() throws Exception { if (acceptorThreadCount == 0) {//接受请求的线程数 acceptorThreadCount = 1; } if (serverSocket == null) { try { if (address == null) { //基于特定端口创建一个ServerSocket对象,准备接受请求 serverSocket = serverSocketFactory.createSocket(port, backlog); } else { serverSocket = serverSocketFactory.createSocket(port, backlog, address); } } catch (BindException orig) { …… } } }
在上面的代码中,我们可以看到此时初始化了一个ServerSocket对象,用来准备接受请求。
如果将其比作赛跑,此时已经到了“各就各位”状态,就等最终的那声“发令枪”了,而Catalina的start方法就是“发令枪”啦:
public void start() { if (getServer() == null) { load(); } if (getServer() == null) { log.fatal("Cannot start server. Server instance is not configured."); return; } if (getServer() instanceof Lifecycle) { try { ((Lifecycle) getServer()).start(); } catch (LifecycleException e) { log.error("Catalina.start: ", e); } } //…… } JIoEndpoint的start方法:
此时会调用Server的start方法,这里我们重点还是关注JIoEndpoint的start方法:
public void start() throws Exception { if (!initialized) { init(); } if (!running) { running = true; paused = false; if (executor == null) { //初始化处理连接的线程,maxThread的默认值为200,这也就是为什么 //说Tomcat只能同时处理200个请求的来历 workers = new WorkerStack(maxThreads); } for (int i = 0; i < acceptorThreadCount; i++) { //初始化接受请求的线程 Thread acceptorThread = new Thread(new Acceptor(), getName() + "-Acceptor-" + i); acceptorThread.setPriority(threadPriority); acceptorThread.setDaemon(daemon); acceptorThread.start(); } } } 从以上的代码,可以看到,如果没有在server.xml中声明Executor的话,将会使用内部的一个容量为200的线程池用来后续的请求处理。并且按照参数acceptorThreadCount的设置,初始化线程来接受请求。而Acceptor是真正的幕后英雄,接受请求并分派给处理过程:
protected class Acceptor implements Runnable { public void run() { while (running) { // 接受发送过来的请求 Socket socket = serverSocketFactory.acceptSocket(serverSocket); serverSocketFactory.initSocket(socket); //处理这个请求 if (!processSocket(socket)) { //关闭连接 try { socket.close(); } catch (IOException e) { // Ignore } } } } } 从这里我们可以看到,Acceptor接受Socket请求,并调用processSocket方法来进行请求的处理。至此,Tomcat的组件整装待命,等待请求的到来。

什么叫做Nginx性能调优呢? 性能调优如何学呢?
这里展示一张Nginx的学习路线图:

让我们先来了解一下Nginx的工作进程
1、Nginx运行工作进程数量
Nginx运行工作进程个数一般设置CPU的核心或者核心数x2。如果不了解cpu的核数,可以top命令之后按1看出来,也可以查看/proc/cpuinfo文件 grep ^processor /proc/cpuinfo | wc -l
[root@lx~]# vi/usr/local/nginx1.10/conf/nginx.confworker_processes 4;[root@lx~]# /usr/local/nginx1.10/sbin/nginx-s reload[root@lx~]# ps -aux | grep nginx |grep -v greproot 9834 0.0 0.0 47556 1948 ? Ss 22:36 0:00 nginx: master processnginxwww 10135 0.0 0.0 50088 2004 ? S 22:58 0:00 nginx: worker processwww 10136 0.0 0.0 50088 2004 ? S 22:58 0:00 nginx: worker processwww 10137 0.0 0.0 50088 2004 ? S 22:58 0:00 nginx: worker processwww 10138 0.0 0.0 50088 2004 ? S 22:58 0:00 nginx: worker process
2、Nginx运行CPU亲和力
比如4核配置:
worker_processes 4;worker_cpu_affinity 0001 0010 0100 1000
比如8核配置:
worker_processes 8;worker_cpu_affinity 00000001 00000010 00000100 0000100000010000 00100000 01000000 10000000;
worker_processes最多开启8个,8个以上性能提升不会再提升了,而且稳定性变得更低,所以8个进程够用了。
3、Nginx最大打开文件数
worker_rlimit_nofile 65535;
这个指令是指当一个nginx进程打开的最多文件描述符数目,理论值应该是最多打开文件数(ulimit -n)与nginx进程数相除,但是nginx分配请求并不是那么均匀,所以最好与ulimit -n的值保持一致。
注:文件资源限制的配置可以在/etc/security/limits.conf设置,针对root/user等各个用户或者*代表所有用户来设置。
* soft nofile 65535* hard nofile 65535
用户重新登录生效(ulimit -n)
4、Nginx事件处理模型
events { use epoll; worker_connections 65535; multi_accept on;} nginx采用epoll事件模型,处理效率高。
work_connections是单个worker进程允许客户端最大连接数,这个数值一般根据服务器性能和内存来制定,实际最大值就是worker进程数乘以work_connections。
实际我们填入一个65535,足够了,这些都算并发值,一个网站的并发达到这么大的数量,也算一个大站了!
multi_accept 告诉nginx收到一个新连接通知后接受尽可能多的连接,默认是on,设置为on后,多个worker按串行方式来处理连接,也就是一个连接只有一个worker被唤醒,其他的处于休眠状态,设置为off后,多个worker按并行方式来处理连接,也就是一个连接会唤醒所有的worker,直到连接分配完毕,没有取得连接的继续休眠。当你的服务器连接数不多时,开启这个参数会让负载有一定的降低,但是当服务器的吞吐量很大时,为了效率,可以关闭这个参数。
5、开启高效传输模式
http { include mime.types; default_type application/octet-stream; …… sendfile on; tcp_nopush on; ……} -
Include mime.types : 媒体类型,include 只是一个在当前文件中包含另一个文件内容的指令。
-
default_type application/octet-stream :默认媒体类型足够。
-
sendfile on:开启高效文件传输模式,sendfile指令指定nginx是否调用sendfile函数来输出文件,对于普通应用设为 on,如果用来进行下载等应用磁盘IO重负载应用,可设置为off,以平衡磁盘与网络I/O处理速度,降低系统的负载。注意:如果图片显示不正常把这个改成off。
-
tcp_nopush on:必须在sendfile开启模式才有效,防止网路阻塞,积极的减少网络报文段的数量(将响应头和正文的开始部分一起发送,而不一个接一个的发送。)
6、连接超时时间
主要目的是保护服务器资源,CPU,内存,控制连接数,因为建立连接也是需要消耗资源的。
keepalive_timeout 60;tcp_nodelay on;client_header_buffer_size 4k;open_file_cache max=102400 inactive=20s;open_file_cache_valid 30s;open_file_cache_min_uses 1;client_header_timeout 15;client_body_timeout 15;reset_timedout_connection on;send_timeout 15;server_tokens off;client_max_body_size 10m;
-
keepalived_timeout :客户端连接保持会话超时时间,超过这个时间,服务器断开这个链接。
-
tcp_nodelay:也是防止网络阻塞,不过要包涵在keepalived参数才有效。
-
client_header_buffer_size 4k:客户端请求头部的缓冲区大小,这个可以根据你的系统分页大小来设置,一般一个请求头的大小不会超过 1k,不过由于一般系统分页都要大于1k,所以这里设置为分页大小。分页大小可以用命令getconf PAGESIZE取得。
-
open_file_cache max=102400 inactive=20s :这个将为打开文件指定缓存,默认是没有启用的,max指定缓存数量,建议和打开文件数一致,inactive 是指经过多长时间文件没被请求后删除缓存。
-
open_file_cache_valid 30s:这个是指多长时间检查一次缓存的有效信息。
-
open_file_cache_min_uses 1 :open_file_cache指令中的inactive 参数时间内文件的最少使用次数,如果超过这个数字,文件描述符一直是在缓存中打开的,如上例,如果有一个文件在inactive 时间内一次没被使用,它将被移除。
-
client_header_timeout : 设置请求头的超时时间。我们也可以把这个设置低些,如果超过这个时间没有发送任何数据,nginx将返回request time out的错误。
-
client_body_timeout设置请求体的超时时间。我们也可以把这个设置低些,超过这个时间没有发送任何数据,和上面一样的错误提示。
-
reset_timeout_connection :告诉nginx关闭不响应的客户端连接。这将会释放那个客户端所占有的内存空间。
-
send_timeout :响应客户端超时时间,这个超时时间仅限于两个活动之间的时间,如果超过这个时间,客户端没有任何活动,nginx关闭连接。
-
server_tokens :并不会让nginx执行的速度更快,但它可以关闭在错误页面中的nginx版本数字,这样对于安全性是有好处的。
-
client_max_body_size:上传文件大小限制。
7、fastcgi 调优
fastcgi_connect_timeout 600;fastcgi_send_timeout 600;fastcgi_read_timeout 600;fastcgi_buffer_size 64k;fastcgi_buffers 4 64k;fastcgi_busy_buffers_size 128k;fastcgi_temp_file_write_size 128k;fastcgi_temp_path/usr/local/nginx1.10/nginx_tmp;fastcgi_intercept_errors on;fastcgi_cache_path/usr/local/nginx1.10/fastcgi_cache levels=1:2 keys_zone=cache_fastcgi:128minactive=1d max_size=10g;
-
fastcgi_connect_timeout 600 :指定连接到后端FastCGI的超时时间。
-
fastcgi_send_timeout 600 :向FastCGI传送请求的超时时间。
-
fastcgi_read_timeout 600 :指定接收FastCGI应答的超时时间。
-
fastcgi_buffer_size 64k :指定读取FastCGI应答第一部分需要用多大的缓冲区,默认的缓冲区大小为。fastcgi_buffers指令中的每块大小,可以将这个值设置更小。
-
fastcgi_buffers 4 64k :指定本地需要用多少和多大的缓冲区来缓冲FastCGI的应答请求,如果一个php脚本所产生的页面大小为256KB,那么会分配4个64KB的缓冲区来缓存,如果页面大小大于256KB,那么大于256KB的部分会缓存到fastcgi_temp_path指定的路径中,但是这并不是好方法,因为内存中的数据处理速度要快于磁盘。一般这个值应该为站点中php脚本所产生的页面大小的中间值,如果站点大部分脚本所产生的页面大小为256KB,那么可以把这个值设置为“8 32K”、“4 64k”等。
-
fastcgi_busy_buffers_size 128k :建议设置为fastcgi_buffers的两倍,繁忙时候的buffer。
-
fastcgi_temp_file_write_size 128k :在写入fastcgi_temp_path时将用多大的数据块,默认值是fastcgi_buffers的两倍,该数值设置小时若负载上来时可能报502BadGateway。
-
fastcgi_temp_path :缓存临时目录。
-
fastcgi_intercept_errors on :这个指令指定是否传递4xx和5xx错误信息到客户端,或者允许nginx使用error_page处理错误信息。注:静态文件不存在会返回404页面,但是php页面则返回空白页!
-
fastcgi_cache_path /usr/local/nginx1.10/fastcgi_cachelevels=1:2 keys_zone=cache_fastcgi:128minactive=1d max_size=10g :fastcgi_cache缓存目录,可以设置目录层级,比如1:2会生成16*256个子目录,cache_fastcgi是这个缓存空间的名字,cache是用多少内存(这样热门的内容nginx直接放内存,提高访问速度),inactive表示默认失效时间,如果缓存数据在失效时间内没有被访问,将被删除,max_size表示最多用多少硬盘空间。
-
fastcgi_cache cache_fastcgi :#表示开启FastCGI缓存并为其指定一个名称。开启缓存非常有用,可以有效降低CPU的负载,并且防止502的错误放生。cache_fastcgi为proxy_cache_path指令创建的缓存区名称。
-
fastcgi_cache_valid 200 302 1h :#用来指定应答代码的缓存时间,实例中的值表示将200和302应答缓存一小时,要和fastcgi_cache配合使用。
-
fastcgi_cache_valid 301 1d :将301应答缓存一天。
-
fastcgi_cache_valid any 1m :将其他应答缓存为1分钟。
-
fastcgi_cache_min_uses 1 :该指令用于设置经过多少次请求的相同URL将被缓存。
-
fastcgi_cache_key http://$host$request_uri :该指令用来设置web缓存的Key值,nginx根据Key值md5哈希存储.一般根据$host(域名)、$request_uri(请求的路径)等变量组合成proxy_cache_key 。
-
fastcgi_pass :指定FastCGI服务器监听端口与地址,可以是本机或者其它。
总结:
nginx的缓存功能有:proxy_cache / fastcgi_cache
-
proxy_cache的作用是缓存后端服务器的内容,可能是任何内容,包括静态的和动态。
-
fastcgi_cache的作用是缓存fastcgi生成的内容,很多情况是php生成的动态的内容。
-
proxy_cache缓存减少了nginx与后端通信的次数,节省了传输时间和后端宽带。
-
fastcgi_cache缓存减少了nginx与php的通信的次数,更减轻了php和数据库(mysql)的压力。
分享2020最新大厂面试真题,需要领取的可以 哦!

8、gzip 调优
使用gzip压缩功能,可能为我们节约带宽,加快传输速度,有更好的体验,也为我们节约成本,所以说这是一个重点。
Nginx启用压缩功能需要你来ngx_http_gzip_module模块,apache使用的是mod_deflate。
一般我们需要压缩的内容有:文本,js,html,css,对于图片,视频,flash什么的不压缩,同时也要注意,我们使用gzip的功能是需要消耗CPU的!
gzip on;gzip_min_length 2k;gzip_buffers 4 32k;gzip_http_version 1.1;gzip_comp_level 6;gzip_typestext/plain text/css text/javascriptapplication/json application/javascript application/x-javascriptapplication/xml;gzip_vary on;gzip_proxied any;gzip on; #开启压缩功能
-
gzip_min_length 1k :设置允许压缩的页面最小字节数,页面字节数从header头的Content-Length中获取,默认值是0,不管页面多大都进行压缩,建议设置成大于1K,如果小与1K可能会越压越大。
-
gzip_buffers 4 32k :压缩缓冲区大小,表示申请4个单位为32K的内存作为压缩结果流缓存,默认值是申请与原始数据大小相同的内存空间来存储gzip压缩结果。
-
gzip_http_version 1.1 :压缩版本,用于设置识别HTTP协议版本,默认是1.1,目前大部分浏览器已经支持GZIP解压,使用默认即可。
-
gzip_comp_level 6 :压缩比例,用来指定GZIP压缩比,1压缩比最小,处理速度最快,9压缩比最大,传输速度快,但是处理慢,也比较消耗CPU资源。
-
gzip_types text/css text/xml application/javascript :用来指定压缩的类型,‘text/html’类型总是会被压缩。默认值: gzip_types text/html (默认不对js/css文件进行压缩)
-
压缩类型,匹配MIME型进行压缩;
-
不能用通配符 text/*;
-
text/html默认已经压缩 (无论是否指定);
-
设置哪压缩种文本文件可参考 conf/mime.types。
-
-
gzip_vary on :varyheader支持,改选项可以让前端的缓存服务器缓存经过GZIP压缩的页面,例如用Squid缓存经过nginx压缩的数据。
9、expires 缓存调优
缓存,主要针对于图片,css,js等元素更改机会比较少的情况下使用,特别是图片,占用带宽大,我们完全可以设置图片在浏览器本地缓存365d,css,js,html可以缓存个10来天,这样用户第一次打开加载慢一点,第二次,就非常快了!缓存的时候,我们需要将需要缓存的拓展名列出来, Expires缓存配置在server字段里面。
location ~* \.(ico|jpe?g|gif|png|bmp|swf|flv)$ {expires 30d;#log_not_found off;access_log off;}location ~* \.(js|css)$ {expires 7d;log_not_found off;access_log off;} 注:log_not_found off;是否在error_log中记录不存在的错误。默认是。
总结:
expire功能优点:
-
expires可以降低网站购买的带宽,节约成本;
-
同时提升用户访问体验;
-
减轻服务的压力,节约服务器成本,是web服务非常重要的功能。
expire功能缺点:
-
被缓存的页面或数据更新了,用户看到的可能还是旧的内容,反而影响用户体验。
解决办法:第一个缩短缓存时间,例如:1天,但不彻底,除非更新频率大于1天;第二个对缓存的对象改名。
网站不希望被缓存的内容:
-
网站流量统计工具;
-
更新频繁的文件(google的logo)。
10、防盗链
防止别人直接从你网站引用图片等链接,消耗了你的资源和网络流量,那么我们的解决办法由几种:
-
水印,品牌宣传,你的带宽,服务器足够;
-
防火墙,直接控制,前提是你知道IP来源;
-
防盗链策略下面的方法是直接给予404的错误提示。
location ~*^.+\.(jpg|gif|png|swf|flv|wma|wmv|asf|mp3|mmf|zip|rar)$ {valid_referers noneblocked www.benet.com benet.com;if($invalid_referer) { #return 302 http://www.benet.com/img/nolink.jpg; return 404; break;}access_log off;} 参数可以使如下形式:
-
none :意思是不存在的Referer头(表示空的,也就是直接访问,比如直接在浏览器打开一个图片)。
-
blocked :意为根据防火墙伪装Referer头,如:“Referer:XXXXXXX”。
-
server_names :为一个或多个服务器的列表,0.5.33版本以后可以在名称中使用“*”通配符。
11、内核参数优化
-
fs.file-max = 999999:这个参数表示进程(比如一个worker进程)可以同时打开的最大句柄数,这个参数直线限制最大并发连接数,需根据实际情况配置。
-
net.ipv4.tcp_max_tw_buckets = 6000 :这个参数表示操作系统允许TIME_WAIT套接字数量的最大值,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。该参数默认为180000,过多的TIME_WAIT套接字会使Web服务器变慢。注:主动关闭连接的服务端会产生TIME_WAIT状态的连接
-
net.ipv4.ip_local_port_range = 1024 65000 :允许系统打开的端口范围。
-
net.ipv4.tcp_tw_recycle = 1 :启用timewait快速回收。
-
net.ipv4.tcp_tw_reuse = 1 :开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接。这对于服务器来说很有意义,因为服务器上总会有大量TIME-WAIT状态的连接。
-
net.ipv4.tcp_keepalive_time = 30:这个参数表示当keepalive启用时,TCP发送keepalive消息的频度。默认是2小时,若将其设置的小一些,可以更快地清理无效的连接。
-
net.ipv4.tcp_syncookies = 1 :开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies来处理。
-
net.core.somaxconn = 40960 :web 应用中 listen 函数的 backlog 默认会给我们内核参数的。
-
net.core.somaxconn :限制到128,而nginx定义的NGX_LISTEN_BACKLOG 默认为511,所以有必要调整这个值。注:对于一个TCP连接,Server与Client需要通过三次握手来建立网络连接.当三次握手成功后,我们可以看到端口的状态由LISTEN转变为ESTABLISHED,接着这条链路上就可以开始传送数据了.每一个处于监听(Listen)状态的端口,都有自己的监听队列.监听队列的长度与如somaxconn参数和使用该端口的程序中listen()函数有关。somaxconn定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数,默认值为128,对于一个经常处理新连接的高负载 web服务环境来说,默认的 128 太小了。大多数环境这个值建议增加到 1024 或者更多。大的侦听队列对防止拒绝服务 DoS 攻击也会有所帮助。
-
net.core.netdev_max_backlog = 262144 :每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
-
net.ipv4.tcp_max_syn_backlog = 262144 :这个参数标示TCP三次握手建立阶段接受SYN请求队列的最大长度,默认为1024,将其设置得大一些可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的连接请求。
-
net.ipv4.tcp_rmem = 10240 87380 12582912 :这个参数定义了TCP接受缓存(用于TCP接受滑动窗口)的最小值、默认值、最大值。
-
net.ipv4.tcp_wmem = 10240 87380 12582912:这个参数定义了TCP发送缓存(用于TCP发送滑动窗口)的最小值、默认值、最大值。
-
net.core.rmem_default = 6291456:这个参数表示内核套接字接受缓存区默认的大小。
-
net.core.wmem_default = 6291456:这个参数表示内核套接字发送缓存区默认的大小。
-
net.core.rmem_max = 12582912:这个参数表示内核套接字接受缓存区的最大大小。
-
net.core.wmem_max = 12582912:这个参数表示内核套接字发送缓存区的最大大小。
-
net.ipv4.tcp_syncookies = 1:该参数与性能无关,用于解决TCP的SYN攻击。

下面贴一个完整的内核优化设置:
fs.file-max = 999999net.ipv4.ip_forward = 0net.ipv4.conf.default.rp_filter = 1net.ipv4.conf.default.accept_source_route = 0kernel.sysrq = 0kernel.core_uses_pid = 1net.ipv4.tcp_syncookies = 1kernel.msgmnb = 65536kernel.msgmax = 65536kernel.shmmax = 68719476736kernel.shmall = 4294967296net.ipv4.tcp_max_tw_buckets = 6000net.ipv4.tcp_sack = 1net.ipv4.tcp_window_scaling = 1net.ipv4.tcp_rmem = 10240 87380 12582912net.ipv4.tcp_wmem = 10240 87380 12582912net.core.wmem_default = 8388608net.core.rmem_default = 8388608net.core.rmem_max = 16777216net.core.wmem_max = 16777216net.core.netdev_max_backlog = 262144net.core.somaxconn = 40960net.ipv4.tcp_max_orphans = 3276800net.ipv4.tcp_max_syn_backlog = 262144net.ipv4.tcp_timestamps = 0net.ipv4.tcp_synack_retries = 1net.ipv4.tcp_syn_retries = 1net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_mem = 94500000 915000000 927000000net.ipv4.tcp_fin_timeout = 1net.ipv4.tcp_keepalive_time = 30net.ipv4.ip_local_port_range = 1024 65000
执行sysctl -p使内核修改生效。
12、关于系统连接数的优化
linux 默认值 open files为1024。查看当前系统值:
# ulimit -n1024
说明server只允许同时打开1024个文件。
使用ulimit -a 可以查看当前系统的所有限制值,使用ulimit -n 可以查看当前的最大打开文件数。
新装的linux 默认只有1024 ,当作负载较大的服务器时,很容易遇到error: too many open files。因此,需要将其改大,在/etc/security/limits.conf最后增加:
* soft nofile 65535* hard nofile 65535* soft noproc 65535* hard noproc 65535
文章到此就结束了
小编给到大家的福利:


十月份马上就要国庆了,寒冷的冬天马上就要来了,为了大家能够面试成功,在吹着暖气的公司里面敲代码,工作,特意为大家准备了一套大厂必备的面试题(涵盖了mybatis,Java核心资料知识点整理,spring cloud Alibaba,Nginx性能调优,tomcat,Linux等......),需要领取的可以 哦!
转载地址:http://lafvi.baihongyu.com/